AUTOR: ARUN GOWTHAM, TRADUCCIÓN POR: JULIO FLORES, PABELON 23 OCTUBRE 2023
Una de las preguntas más comunes que tienen los equipos cuando exploran por primera vez el uso del mantenimiento predictivo es: “¿Son los datos lo suficientemente buenos como para realizar el análisis?” La respuesta a esta pregunta está matizada por el objetivo de confiabilidad y la calidad de los datos disponibles.
Antes de profundizar en la respuesta, en la tabla se ofrece una práctica visión de alto nivel del tipo de análisis de mantenimiento predictivo posible a partir de los datos disponibles:
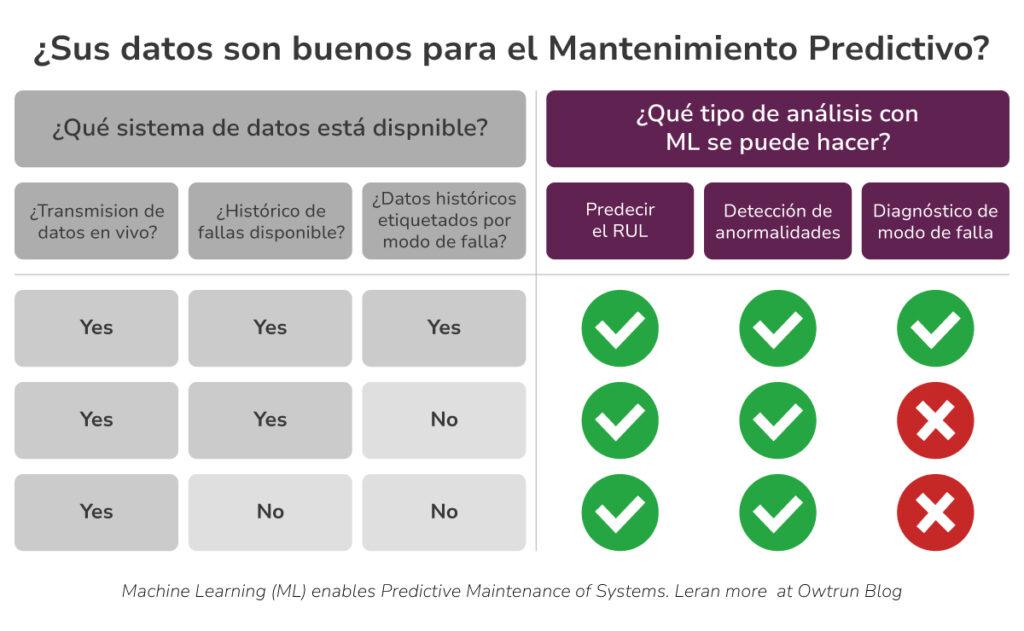
Sistema
Puede ser un solo equipo (activo) o una flotaDatos del sistema
Pueden ser datos de rendimiento (temperatura o presión del proceso) o datos de condición (vibración)Flujo de datos en vivo
Puede ser continuo (series temporales) o discreto (recopilación manual de datos)Registros históricos de fallas
Pueden ser datos de vida completa (desde el estado normal hasta el estado de falla) o solo datos de tiempo hasta la falla. Cuando no se dispone de datos, se puede utilizar el modelado de degradación con umbrales.Etiquetas
La agrupación de errores en función de los modos de error. Puede ser solo dos clases: Estado normal o fallido; o varias clases: Modo de falla A o B o C.
Cada uno de los análisis enumerados anteriormente ofrece a los ingenieros de confiabilidad y mantenimiento la capacidad de comprender el rendimiento y ajustar el plan de mantenimiento.
Predecir RUL
Responde a la pregunta “¿Cuánto tiempo funcionará el sistema antes de fallar?” Este análisis predice la vida útil total remanente (RUL) considerando el estado operativo actual y el rendimiento históricoDetectar anomalías
Responde a la pregunta “¿Qué sucedió?” Este análisis se utiliza para monitorear el funcionamiento del sistema para detectar desviaciones del rendimiento normal. Todos los mecanismos de falla exhiben un síntoma antes de la falla total y este análisis lo marca como una advertencia tempranaModo de diagnóstico de fallas
Responde a la pregunta “¿Por qué se produjo la falla?” El análisis de la causa raíz es la herramienta más poderosa en la mejora de la confiabilidad y este análisis ayuda a identificar la causa más probable de anomalía a partir de los patrones de similitud de los datos históricos.
Dados estos requisitos de datos para varios análisis, la siguiente pregunta natural que surge es “¿Cuántos de estos datos se necesitan? Una regla general para iniciar cualquier algoritmo de machine learning es tener 10 veces el tamaño de los datos que el número de características analizadas. El principal determinante para decidir qué datos utilizar y cuánto es el objetivo de fiabilidad del análisis. ¿Qué está tratando de optimizar el equipo? ¿Qué tan crítico es el resultado? ¿Cómo impacta en el negocio?
Artículo original: Is your Data Good Enough for Machine Learning-Based Predictive Maintenance (PdM)? | Gowtham, A. (2023). Accendo Reliability. Retrieved 23 October 2023